
When the tokens run out

The Hidden Cost of "Unlimited" AI: Why Fixed-Price AI Tool Plans May Be Economically Unsustainable
Every AI response has a real, variable compute cost—measured in tokens processed and GPU time consumed. As power users push deeper into coding agents, long-context research, and multimodal workflows, their per-user inference costs can exceed the flat monthly subscription fee. OpenAI, Anthropic, and Microsoft—have now publicly signaled that the current fixed-price model is under strain, and structural changes to pricing appear imminent.
As we race towards IPOs for Anthropic, OpenAI and SpaceX (which includes xAI) it’s more important than ever to understand the economics of AI tokens. Public markets will force scrutiny upon what is currently not a well-understood and looming problem for AI strategy and adoption.
How Token-Based Costs Work
Unlike traditional software where serving an additional user costs nearly nothing, large language models incur a fresh computational cost for every query. Text is processed in units called tokens (roughly 3–4 characters each). Both the text you send (input tokens) and the text the model generates (output tokens) require GPU computation, and providers price them separately.
Input vs. output tokens: Output tokens are generally more expensive because generating new text is more compute-intensive than reading existing text. For GPT-5.5, OpenAI's API charges $5 per million input tokens and $30 per million output tokens OpenAI API Pricing | OpenAI. Anthropic's Claude Opus 4.7 via API costs $5 per million input tokens and $25 per million output tokensPricing - Claude API Docs. Google’s Gemini 3.1 Pro Preview charges up to $4 per million input tokens and up to $18 per million output tokensGemini Developer API pricing | Gemini API | Google AI for Developers
Training vs. inference: Training a frontier model costs tens of millions of dollars but is a one-time expense. The ongoing cost is inference—running the model to answer each user query. That inference cost scales directly with how many tokens the model reads and writes.
Context windows multiply the bill: Modern models accept enormous inputs. In March, 2026 Anthropic expanded Claude's context window for Opus 4.6 and Sonnet 4.6 models to support up to 1 million tokens (roughly 750,000 words) 1M context is now generally available for Opus 4.6 and Sonnet 4.6 | Claude. If a user fills that window with document uploads, the model must process all 750,000 tokens each time—dramatically increasing per-query cost.
Multimodal inputs add overhead: OpenAI's real-time audio model (gpt-realtime-1.5) charges $32 per million audio input tokens and $64 per million audio output tokens—far more than text rates for the same model. Similarly, image inputs for OpenAI incur their own metering according to the model and the image size. Each modality beyond text inflates the compute bill.
Current Subscription Prices
Consider the main commercially available AI chat tools and their premium plans:
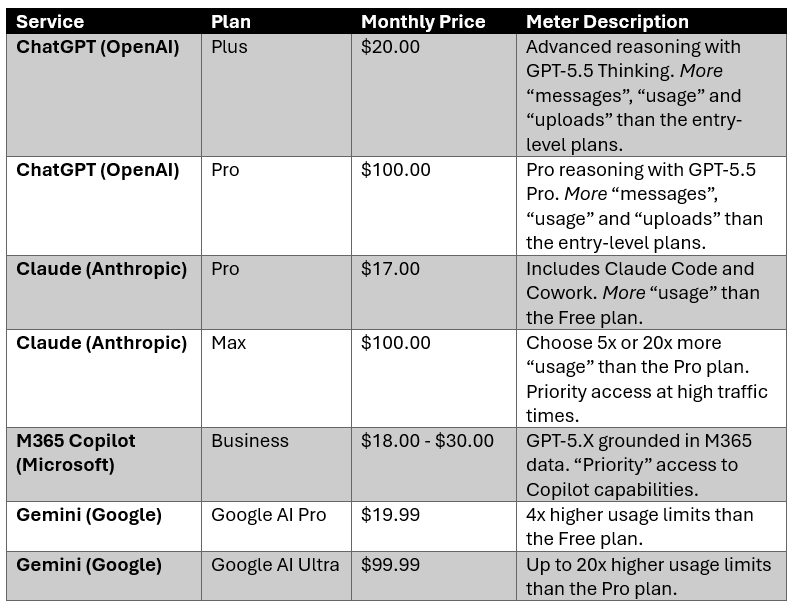
Note the language used to describe the service indicating the metered nature. The terms “usage”, “messages”, “uploads” and “priority” become a proxy for the underlying token and resource consumption.
The Math: When a $20 User Costs More Than $20
Sam Altman disclosed in mid-2025 that the average ChatGPT query consumes approximately 0.34 watt-hours of electricity and costs the company less than one cent. At that rate, a typical user who sends fewer than 2,000 queries per month stays within a $20 cost envelope. But "typical" is doing a lot of work in that sentence.
Illustrative heavy-user scenario (using published API rates as a proxy for inference costs):
Focusing on OpenAI and ChatGPT Plus for a moment. Assume a power user sends 50 substantive queries per day, averaging 500 input tokens and 1,500 output tokens each, for 30 days:
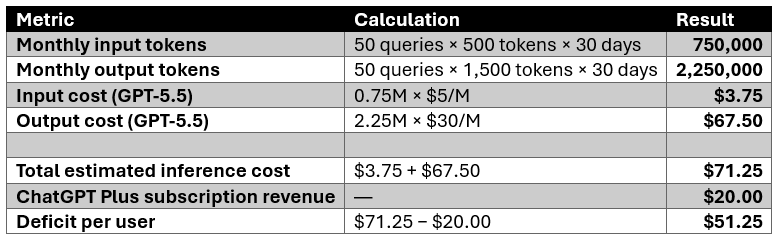
Similar deficits can be calculated for Claude and could reasonably be assumed for Microsoft – seeing at Microsoft offers OpenAI and Anthropic models in M365 Copilot.
Important caveats: API prices include the provider's margin, so internal inference costs are probably somewhat lower. Providers also use caching, batching, and lighter models to reduce per-query costs in consumer products. However, the scenario above assumes moderate-length queries—not the extreme case of filling a 100,000-token context window, which would multiply costs by an order of magnitude per session.
These are not hypothetical concerns. Altman admitted directly: "Insane thing: we are currently losing money on openai pro subscriptions! people use it much more than we expected"—referring to the $100/month ChatGPT Pro tier, where even at ten times the Plus price, heavy usage exceeded revenue. [techstartups.com]
Why the Problem Gets Worse Over Time
Usage per subscriber is accelerating. Anthropic's head of growth, Amol Avasare, described the shift candidly: "When we launched Max a year ago, it didn't include Claude Code, Cowork didn't exist, and agents that run for hours weren't a thing… The way people actually use a Claude subscription has changed fundamentally. Engagement per subscriber is way up."[arstechnica.com]
Several structural forces are compounding costs:
Agentic workflows: AI "agents" chain multiple model calls autonomously. A single user request can trigger dozens of inference passes under the hood. Avasare noted that "long-running async agents are now everyday workflows", meaning what once was one query can now be a cascade of many. [arstechnica.com]
Coding tools as token furnaces: Claude Code and GitHub Copilot's agent mode process entire codebases as context. One Claude Pro user described hitting strict hourly token limits after just 30–60 minutes of Claude Code usage, then being locked out for 3–4 hours—and reaching the weekly cap by day four, losing access for the remaining three days. That level of throttling implies the actual token burn rate far exceeds what the $20 tier is designed to absorb. [arstechnica.com]
Power users are a small but costly minority. Anthropic's test removing Claude Code from the Pro plan targeted only ~2% of new prosumer signups—yet that 2% was consuming enough compute to threaten the experience for everyone else, leading to "occasional outages and other problems for the service". [arstechnica.com]
Growing user base: OpenAI reported 350 million monthly users by mid-2024, up from 100 million just three months earlier, with around 10 million paying $20/month for ChatGPT Plus. As the user base grows and AI assistants become embedded in professional workflows, average usage intensity will likely rise. [techstartups.com]
What Providers Are Already Doing About It
The clearest evidence that current pricing is unsustainable comes from the providers' own actions:
OpenAI is openly reconsidering its pricing model. ChatGPT head Nick Turley, speaking on the Bg2 Pod podcast in March 2026, compared unlimited AI to unlimited electricity: "It's possible that in the current era, having an unlimited plan is like having an unlimited electricity plan. It just doesn't make sense." Turley added that he would be "incredibly surprised" if pricing didn't significantly evolve. Sam Altman has articulated a broader vision: "We see a future where intelligence is a utility like electricity or water and people buy it from us on a meter and use it for whatever they want to use it for".
Anthropic in April 2026 briefly removed Claude Code access from its $20 Pro plan for a test group, restricting it to the $100+ Max tier. The company had already implemented weekly token caps and tighter limits during peak hours. After backlash, Avasare committed: "When we do land on something, if it affects existing subscribers you'll get plenty of notice before anything changes"—but the test confirmed that the $20 price point cannot sustainably support heavy agentic usage. [arstechnica.com]
Microsoft/GitHub took the most dramatic step. In April 2026, GitHub paused new sign-ups for Copilot Pro, Pro+, and Student plans, citing rising compute costs. Internal documents obtained by journalist Ed Zitron revealed that Microsoft plans to move all GitHub Copilot customers to token-based billing starting in June 2026. [wheresyoured.at]
Counterarguments: Why It Might Still Work
Average user cost remains low. Altman's disclosure that a typical query costs less than one cent means a casual user sending 20–30 queries per day would cost OpenAI roughly $6–$9 per month—well within the $20 budget. The model survives as long as light users subsidize heavy ones. Much like gym membership, the less frequent users effectively subsidize the regulars.
Breakage is real. Many subscribers pay $20/month and use the service infrequently, similar to gym memberships. Their unused capacity covers the power users. This cross-subsidy is standard in subscription businesses.
Enterprise revenue offsets consumer losses. Microsoft 365 Copilot charges $30/user/month on annual commitments—50% more than ChatGPT Plus—and enterprise workflows tend to be more predictable. OpenAI projects its revenue will climb to $100 billion by 2029, suggesting expectations that enterprise and API income will scale faster than consumer plan losses. [techstartups.com]
Inference costs are falling. Hardware improvements, model distillation (smaller models mimicking larger ones), and caching reduce cost per token over time.
Implicit throttling provides a ceiling. Providers already impose rate limits, peak-hour restrictions, and context caps that prevent truly unlimited usage in practice. These de facto limits keep the average cost per user below the break-even point.
The tradeoff: These mitigating factors buy time but do not eliminate the structural problem. As more users adopt agentic workflows, as context windows grow, and as multimodal features proliferate, the share of heavy users grows and the average cost per subscriber creeps upward—eventually compressing or eliminating the margin that light users create.
Likely Outcomes: What Changes to Expect
Based on the signals already in the market:
Usage-based or hybrid pricing. The strongest signal. Both OpenAI (Altman's "metered utility" vision) and Microsoft (Copilot's token billing rollout) are moving toward models where users pay a base fee plus metered usage above a threshold. Anthropic already prices its API on a per-token basis and is tightening consumer plan limits. [firstpost.com] [wheresyoured.at]
Tiered model access. Lower-priced plans will likely be restricted to cheaper, smaller models. GitHub Copilot already limits its free tier to Haiku 4.5 and GPT-5 mini, reserving Claude Opus 4.7 for Pro+. Expect similar stratification from OpenAI and Anthropic. [github.com], [github.com]
Hard usage caps with transparent overage charges. Rather than opaque throttling, providers may formalize monthly token budgets. GitHub Copilot already charges per additional premium request—a template that other services could adopt. [github.com]
Price increases. OpenAI's internal documents contemplated raising ChatGPT Plus from $20 to $22 in the near term and $44 within five years. If competitor pricing moves in tandem, consumers may accept gradual increases. [techstartups.com]
Feature segmentation. Expensive capabilities (large context, code execution, image analysis, real-time audio) may become premium add-ons rather than bundled features. Anthropic's test of removing Claude Code from the $20 plan is a direct preview of this approach. [arstechnica.com]
Conclusion
The era of flat-rate, all-you-can-use AI subscriptions was made possible by a market-share land grab in which providers absorbed losses to build user bases. That phase is ending. OpenAI acknowledges losing money on its own Pro tier. Anthropic's infrastructure is strained by a small minority of heavy users. Microsoft is abandoning request-based pricing for explicit token metering.
For moderate users, the transition may be barely noticeable—a cheap plan with a generous allowance will likely remain available, particularly as inference costs continue to fall with hardware improvements and model optimization. For power users running multi-hour agent sessions, uploading entire codebases, or processing images and audio daily, the message from all three providers is increasingly clear: intelligence is becoming a metered utility, and pricing will reflect actual consumption.